

今回はコマ自動切り取りシステム「ミヅハノメ」の特徴と主な機能を説明したいと思います。
ミヅハノメのGUI(操作画面)はこのようになっています
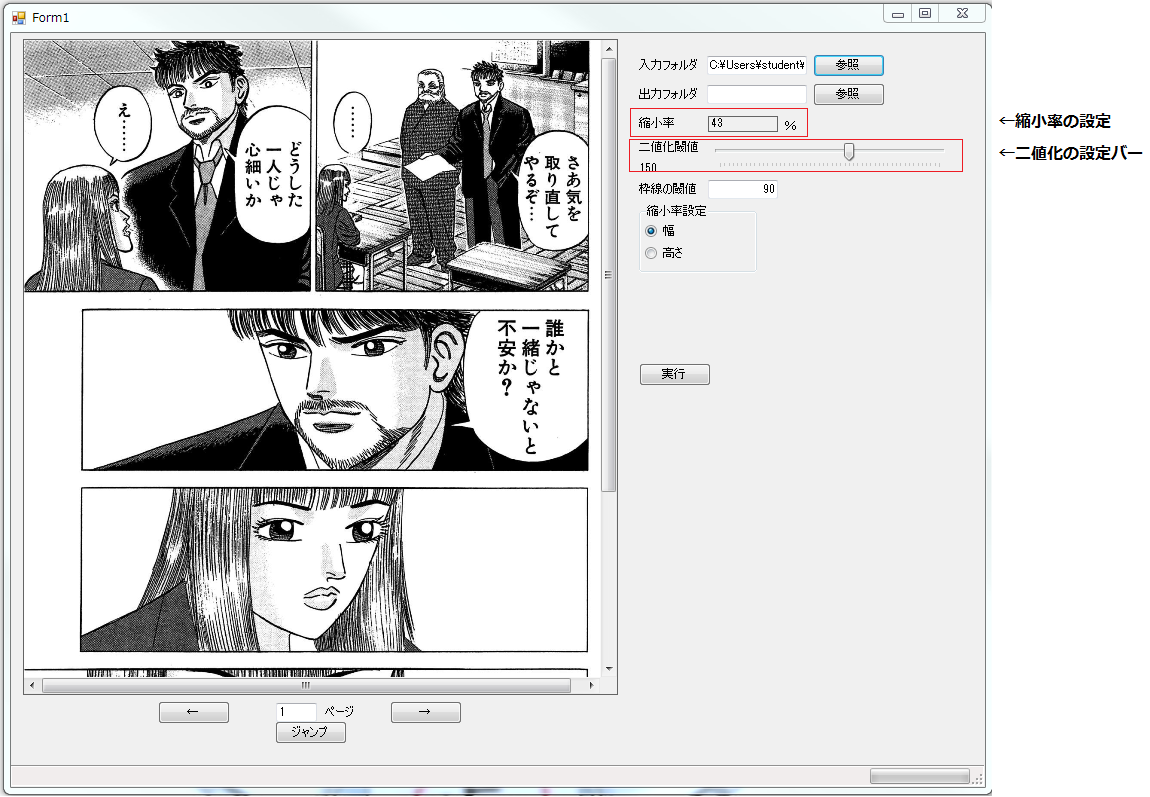
「二値化」や縮小率といった、皆さんが普段あまり見慣れない言葉がいくつかあるかと思います。これらの設定によってミヅハノメは他の切り取りシステムではできないような、正確なコマの自動切り取りを可能としています。縮小率と二値化の設定方法と必要性を説明します。
画像には、縦横比が同じものでも、画像そのものの大きさが異なるものが存在します。その大きさを解像度と言います。この解像度が大きいほど鮮明できれいな画像になるのですが、大きすぎるとファイルサイズが大きくなってしまい、扱いにくくなるデメリットがあります。
ミヅハノメでは一時的に画像を縮小して、コマの切り取りの処理速度を飛躍的にあげることに成功しています。それが縮小率の項目になるということです。この値の設定方法は簡単で、コマとコマの余白が一番狭い場所をクリックするだけで適切な縮小率の設定が可能となっています。解像度がとても高くスキャンされている漫画も数多くありますが、ミヅハノメでは問題なく切り取りが可能です。
3.二値化の設定
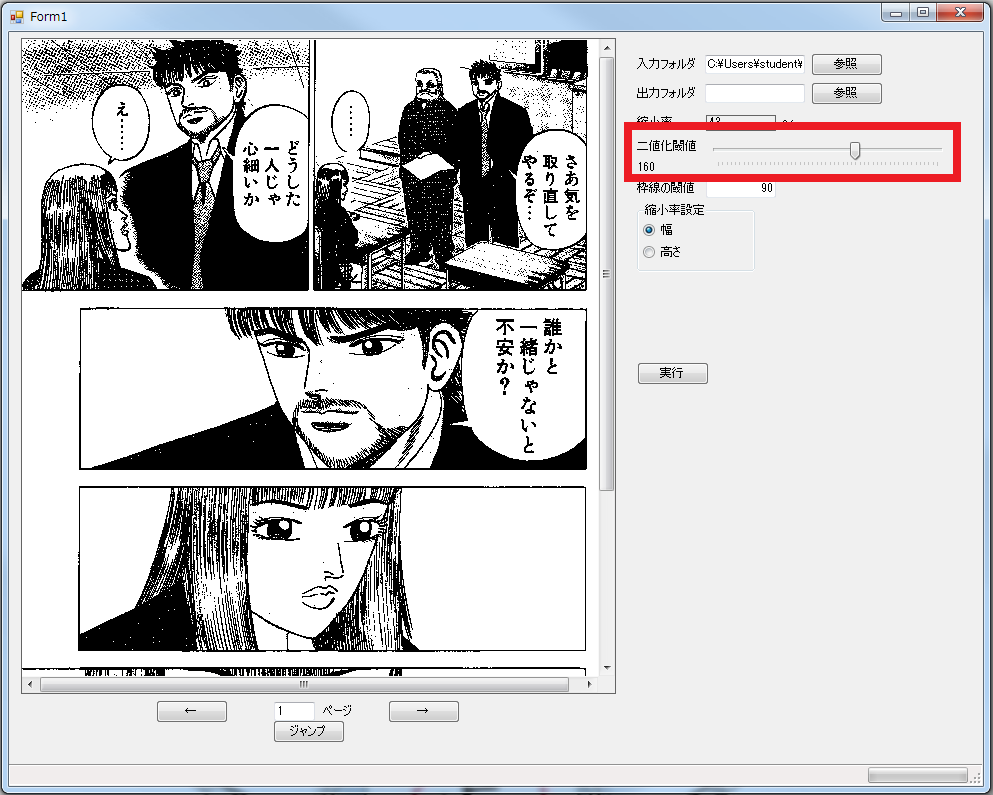
二値化とは、画像を白と黒の二色にはっきりと分ける画像処理のことを言います。この処理は自動コマ分割をする前処理として重要になる工程です。コマを抽出するには、コマの枠線を認識する必要があります。スキャンした漫画は、白い部分が焼けて茶色っぽく変色しているなど状態は様々です。こういった様々な状態の漫画すべてを正確に切り取る為の二値化を簡単に行えることにミヅハノメは成功しました。二値化の値の設定にはGUIの設定バーを使います。二値化の値は、漫画の状態によって左右されるため、一度手動で設定し、精度を高める必要があります。その作業の効率化を図る為、設定バーを利用しています。
上記で紹介したようにその漫画に合わせたパラメータを手動で設定します。そのパラメータで2値化とエッジ検出を行い、その後直線を探索します。

この直線検出には一般的にハフ変換といわれるものが利用されていますが、コマ抽出において、ハフ変換では様々な問題があるので、ミヅハノメでは独自のアルゴリズムで検出しています。
次に、コマ抽出の精度向上のために処理する範囲を細かく分割します。その方法は、漫画の特徴も考え、横で分割する。直線検出した際に、端から端までの横線に注目し分割します。

今回の場合では、4つの領域に分割でき、これを順番に処理します。
分割した領域を順番にコマの抽出処理を行います。その方法は、直線抽出で抽出した線でコの字または、L字型になっている箇所を探します。そこで切り取り、コマとします。

このように、コの字・L字型でコマを抽出します。ここでも、長い直線から探索するなどの工夫があります。
今回の例の画像のように、単純なコマ割りならここまでの処理でコマ抽出ができるのですが、漫画には様々なコマ割りがありそれらの抽出もできるような処理がミヅハノメには、まだまだあります。次回はそちらを説明したいと思います。

